Отбой паники: новый алгоритм Google посадил аппетиты ИИ на диету и остановил рост цен на оперативку
Новый алгоритм TurboQuant ускоряет работу больших языковых моделей в восемь раз и не требует переобучения

Отбой паники: новый алгоритм Google посадил аппетиты ИИ на диету и остановил рост цен на оперативку / Фото: freepik
Одна из главных проблем современного искусственного интеллекта — это даже не то, что он иногда лжет. А то, сколько памяти он при этом потребляет. Google Research решил взяться за эту проблему всерьёз — и представил алгоритм TurboQuant, который, по предварительным результатам, сокращает потребность в памяти в шесть раз без какой-либо потери качества ответов.
Детали
Что такое KV-кэш и почему он раздут
Чтобы понять, что именно решает TurboQuant, нужно разобраться в природе больших языковых моделей. На самом деле они ничего не «знают» в классическом понимании — они оперируют векторами, которые отражают семантические связи между словами и понятиями. Чтобы не рассчитывать эти связи заново каждый раз, модель хранит их в так называемом кеше «ключ-значение» — своего рода цифровой шпаргалке. Именно этот кеш и становится главным пожирателем оперативной памяти.
Стандартное решение — квантование, то есть снижение точности вычислений. Но здесь возникает знакомая дилемма: чем агрессивнее сжимаешь, тем хуже получаешь результат. TurboQuant заявляет, что нашёл способ обойти этот компромисс.
Как это работает: полюсы и один бит коррекции
Алгоритм TurboQuant состоит из двух взаимодополняющих техник. Первая — PolarQuant. Вместо того чтобы хранить вектор в стандартных координатах XYZ, система преобразует его в полярные: радиус (сила сигнала) и направление (его смысл). Это похоже на разницу между указаниями «пройдите три квартала на восток и четыре на север» и просто «пройдите пять кварталов под углом 37 градусов» — меньше слов, тот же результат, меньше ресурсов.
Но даже PolarQuant может накапливать мелкие ошибки. Здесь вступает в действие вторая техника — Quantized Johnson-Lindenstrauss, или QJL. Она добавляет к модели один бит коррекции на каждый вектор — буквально плюс один или минус один — и благодаря этому сохраняет ключевые взаимосвязи между данными. Результат — более точная оценка внимания, которая является основой того, как нейросеть решает, какая информация вообще важна.
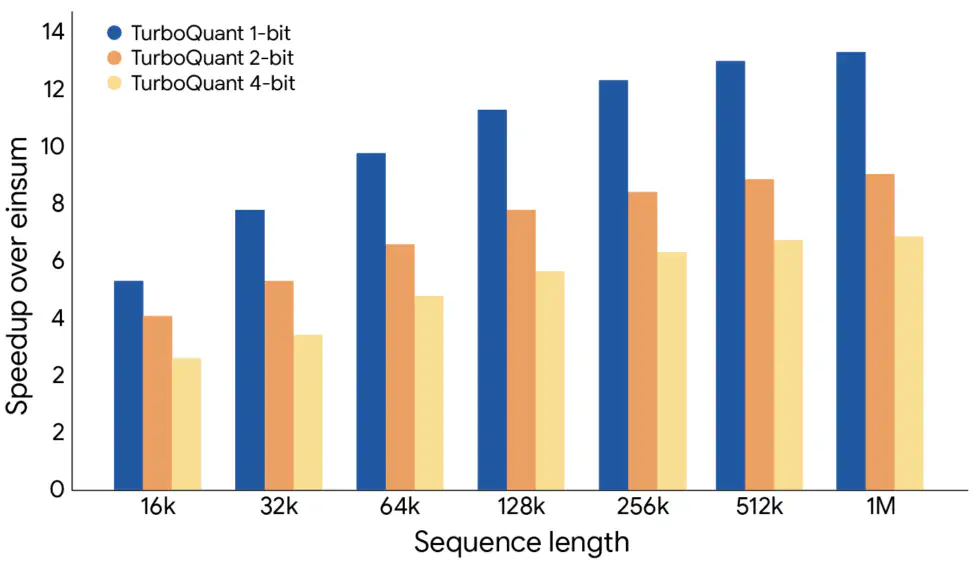
Цифры, которые трудно игнорировать
Google тестировал TurboQuant на открытых моделях Gemma и Mistral в режиме длинного контекста. Результаты: шестикратное сокращение использования KV-кеша, восьмикратное ускорение вычислений внимания по сравнению со стандартными 32-битными ключами на ускорителях NVIDIA H100. При этом алгоритм квантует кеш до 3 бит — и не требует переобучения модели. То есть его можно применять к уже существующим системам.
Рынок уже отреагировал
Новость дошла до инвесторов быстрее, чем до большинства технологических обозревателей. После анонса акции производителей оперативной и флеш-памяти — Micron Technology, Western Digital, Seagate — заметно просели. Логика проста: если ИИ требует в шесть раз меньше памяти, спрос на неё может упасть. Аналитики, впрочем, призывают не спешить — перенести лабораторные результаты в реальное производство сложнее, чем кажется, а общий спрос на память в ближайшие годы всё равно прогнозируется растущим.
Что это значит для обычного пользователя
Если TurboQuant найдёт реальное применение, эффект почувствуется на двух уровнях. Во-первых, корпоративный ИИ станет дешевле в обслуживании — меньше серверов, меньше затрат. Во-вторых, и это интереснее, мощные языковые модели могут появиться непосредственно на смартфонах — без отправки ваших данных в облако. С учётом аппаратных ограничений мобильных устройств, именно здесь такие алгоритмы сжатия имеют наибольший практический потенциал.
Впрочем, есть и менее оптимистичный сценарий: компании могут просто использовать освободившуюся память для запуска ещё больших и более сложных моделей. Скорее всего, произойдёт и то, и другое.
Однако пока одни инженеры работают над эффективностью вычислений, другие находят для искусственного интеллекта менее однозначное применение. Пока технологии сжатия открывают новые горизонты для смартфонов, в Большом Манчестере ИИ стал инструментом для идеологической «чистки» школьных библиотек. Используя алгоритмы для анализа содержания, администрация одной из средних школ провела масштабную ревизию, в результате которой с полок исчезло почти 200 книг. Под цензурный нож нейросети попали не только подростковые «Сумерки» Стефани Майер, но и классика антиутопии — «1984» Джорджа Оруэлла. Более того, искусственный интеллект признал «неподходящими» автобиографию бывшей первой леди США Мишель Обамы и чувственный роман Николаса Спаркса «Дневник памяти», вызвав волну дискуссий о границах доверия алгоритмам в вопросах культуры и воспитания.
Читайте ещё:
- Техно-маникюр: Ученые разработали инновационный лак для ногтей, который позволяет взаимодействовать с сенсорными дисплеями.
- Новая эра Apple Maps: Этим летом в картографическом сервисе Apple появится реклама — что это изменит для пользователей и бизнеса.
- Меньше, чем соль: Создан уникальный мозговой имплантат: он крошечный, работает без батареек и передаёт данные с помощью света.
Не пропустите интересное!
Подписывайтесь на наши каналы и читайте новости в удобном формате!





